
Speech Recognition is a technology that has fascinated and disappointed doctors for more than 25 years. Dictate IT has been developing Speech Recognition solutions in our AI labs since 2014 and outlined here is a brief history of the science behind the technology and a reflection on why it might be the right time to give it a second look.
The ability for machines to recognise and respond to human speech has been a desire since the outset of computing. Early computer scientists wished they could interact with their creations as they did with their colleagues – by talking.
The Post War Period – The birth of the Computer Age
The first machine capable of recognizing human speech was invented in 1952 and named ‘Audrey’ by Bell Labs in the US. She could recognise spoken numbers from 1 to 9. Ten years later, IBM released ‘Shoebox’ which had the ability to recognise simple calculations and input them into a calculator. In the UK, scientists worked to improve recognition using statistical information concerning allowable phonemes in English, and in the USSR they pioneered dynamic time warping to cope with variations in speaking speed. Ask typists in your surgery about the variations in the speed of speech patterns and you will understand the significance of this.
Progress Slows after a promising start
By the 1970s progress had slowed, hampered by the idea that to improve recognition, machines would need to ‘understand’ speech, something that turned out to be unnecessary for the task of recognition and something which still eludes us today.
The late 70s and early 80s saw the introduction of two key new approaches: n-gram language models and Hidden Markov Models (HMMs).
N-gram language models describe the probability of a sequence of words, and are often contextual dependant. For example in the medical dictation domain, the tri-gram “This charming gentleman” is more likely than “This charming pineapple”. This probability allows speech recognition to go beyond just the phonetic information in the audio.
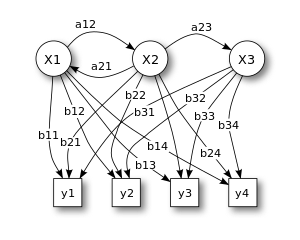
Hidden Markov Models are variants of techniques developed in the 1960s to aid prediction in the US defence industry, in turn based on maths outlined by the Russian Andrey Markov in the middle of the 20th century. Markov models aim to simplify prediction of a future state by only using the current state, rather than needing to use many prior states. Adoption of HMMs for speech recognition, coupled with the increases in computer power needed to feasibly run them produced huge leaps in accuracy and vocabulary size. HMMs continued to dominate speech recognition approaches for the next 25 years.
During the 90s and 00s, the PC enabled HMM-based speech recognition to become more widely available to consumers. Accuracy continued to improve, though began to plateau in the early 00s and still required a degree of per user training and manual correction, based on a speaker-dependent individual profile. Thus speech recognition acquired a slightly jaded reputation as being ‘not quite good enough’ for normal usage. When you last tried speech recognition on your PC to dictate a medical report you probably used a system that used an HMM acoustic model. The results would have been interesting – but not good enough and you probably concluded that it was not for your practice.
Enter the Neural Network and Machine Learning
Artificial Neural Networks (ANNs) were first described in the 1940s, and are networks of nodes and connections inspired by the workings of biological neurons. As with real neurons, as the network ‘learns’ some connections between nodes become stronger, some weaker. The difference from classic computer programming was that ANNs ‘learn’ by themselves rather than being driven entirely from hand-crafted rules given to them by their human programmers. It wasn’t until the 1980s that computing power was sufficient to realise the theoretical technique and interest in neural networks surged with hopes of (strong) Artificial Intelligence based on this biological model. The concept was applied to tasks like speech recognition, but without much success compared to the dominant HMMs. General interest in ANNs declined.
However, in the early 00s, a specific kind of ANN method called Deep Learning began to emerge as a potentially superior alternative. In particular, a collaboration between researchers at Google, Microsoft, IBM, and the University of Toronto showed how Deep Learning techniques could bring significant improvements to many areas including speech, image, and handwriting recognition.
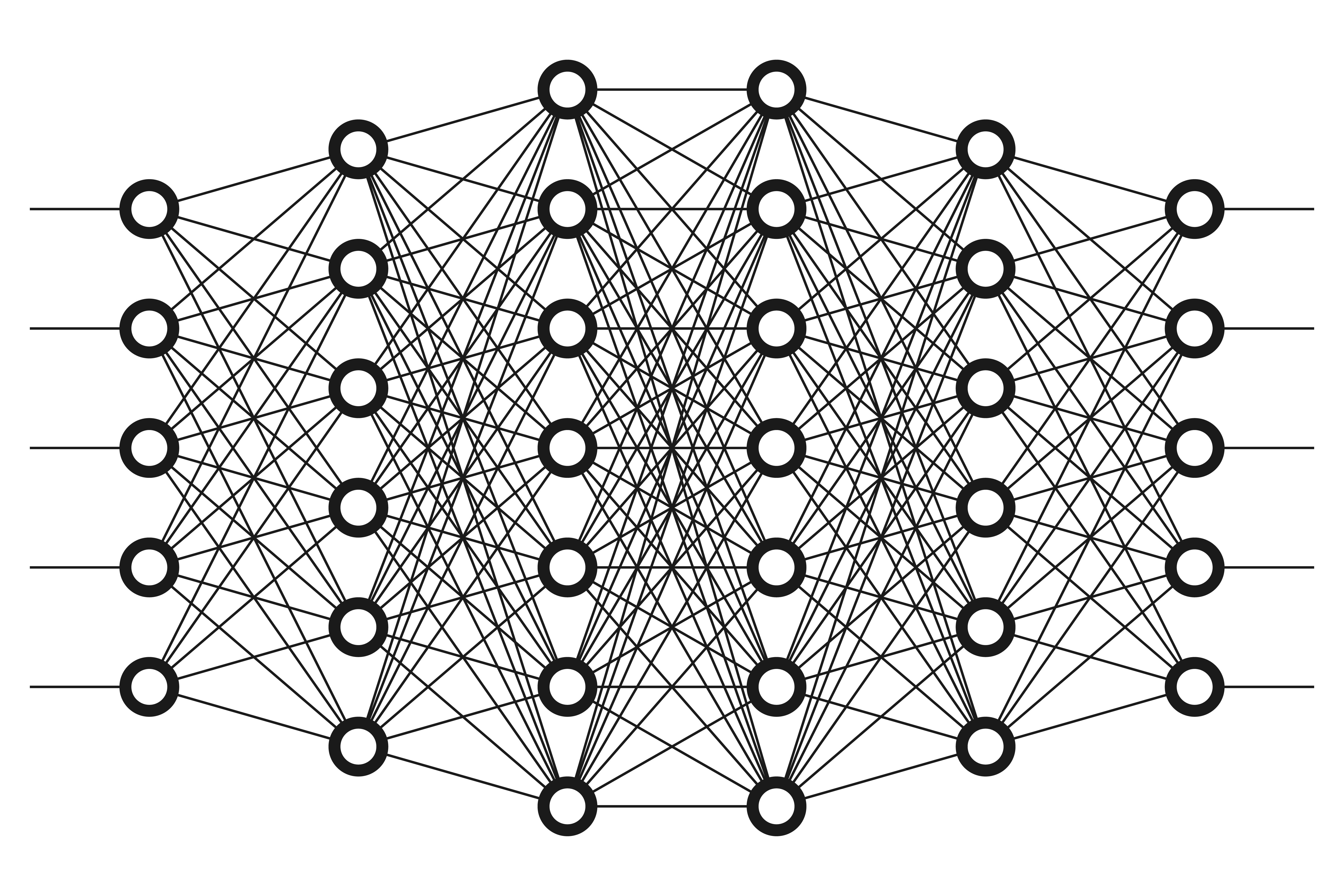
Deep Learning uses Neural Networks that are ‘deep’ by virtue of having multiple layers of nodes between their input and output layers. In speech recognition the input being a segment of audio and the output a piece of text. Each layer ‘learns’ to transform the input to the output in a slightly different way. In 2009 a researcher at Google realised that by using Graphics Processing Units they could massively speed up the training of Deep Neural Networks (DNNs), dramatically shortening the time taken to experiment with new models. By 2012 it was clear that DNNs were outperforming old approaches in multiple fields and this kicked off the huge industry interest and public awareness about the use of ‘AI’.

DNNs are now used by all the major consumer speech recognition products you may be familiar with: Siri, Alexa, Cortana, Google Home/Nest, etc.
Dictate IT Neural Net Stack
Dictate IT began developing its own Deep Neural Network-based speech recognition in 2014. We have always focused on UK medical report recognition. The state of the art is changing constantly, but we currently use two kinds of neural networks:
- An acoustic model based on a factorised Time-Delay Neural Network (TDNN-F)
- An AWD-LTSM language model (aka an ASGD Weight-dropped Long Short Term Memory model
This allows us to provide unmatched highly-accurate speech recognition for UK medical dictation, with no training period required, while covering a wide range of the accents found in the NHS. If you’ve not used medical speech recognition in the last few years, we think you will be impressed by the improvements in the field.